


络续低廉大碗的特色,DeepSeek V3发布即开源。
还用53页论文 ,共享训 练细节。
更要紧的是,大众第一时期在论文中发现了要道细节:
实践历程,低廉又省钱!
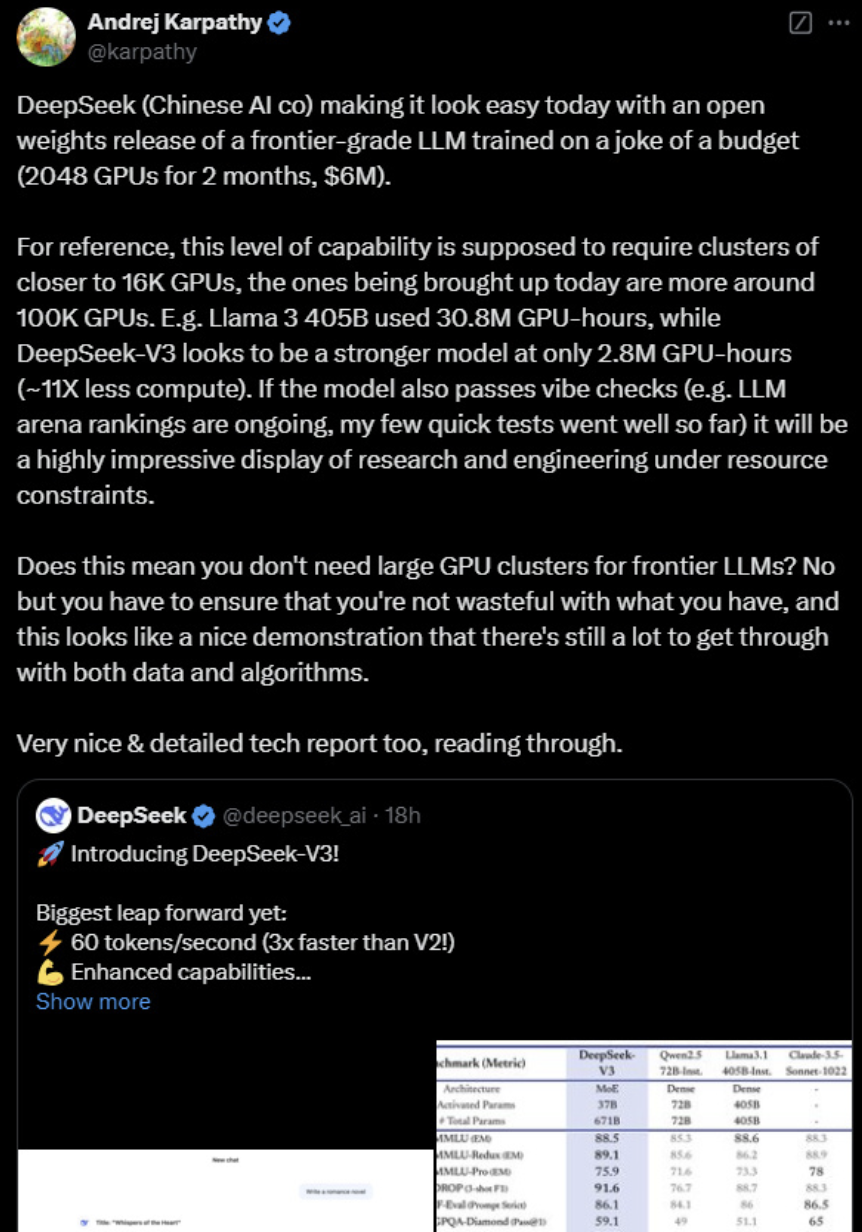
DeepSeek 用十分之一的算力,作念出了和 GPT-4o 及 Claude-3.5-Sonnet 性能迥殊的模子!
DeepSeek V3所有这个词实践历程仅用了不到280万个GPU小时。
对比参考:Llama 3 405B的实践时长是3080万GPU小时。
实践671B的DeepSeek V3的资本是557.6万好意思元(约合4070万东说念主民币)。
而同类模子,或者需要1.5万块 H100,DeepSeek用了 2048 块H800就作念出来了。
国外对deepseek的赞赏和不明,远高于国内。
OpenAI首创成员AK对此赞说念:
DeepSeek V3让在有限算力预算上进行模子预实践这件事变得容易。
DeepSeek V3看起来比Llama 3 405B更强,实践耗尽的算力却仅为后者的1/11。
Meta科学家田渊栋,说DeepSeek V3的实践,看上去是“黑科技”: 这短长常伟大的职责。
Menlo Venture的投资东说念主也欷歔: “53 页的技艺论文是黄金” (53-page technical paper is GOLD)。
英伟达高等磋商科学家Jim Fan,转发OpenAI首创成员AK的推文默示: 资源狂放是一件好意思好的事情。 在粗暴的东说念主工智能竞争环境中,生计本能是赢得絮叨的主要能源。
“我蔼然 DeepSeek 很潜入。旧年他们推出了最好的开源模子之一,超卓的OSS模子给买卖前沿 LLM 公司带来了弘远压力,迫使它们加速法子。”
前阿里巴巴副总裁贾扬清以为:
DeepSeek 的收效是简便的灵巧和实用观点在起作用,在蓄意和东说念主力有限的情况下,通过智能磋商产生最好效果。

论文收尾,再次强调了 「以开源精神和恒久观点追求普惠 AGI」。
固然“小力出遗迹”亦然相对的,因为公司本身家底殷实。
幻方量化是国内惟一公开声称有领有万张英伟达A100显卡的企业,其算力储备量就算是在一众互联网公司科技公司里也豪不逊色。

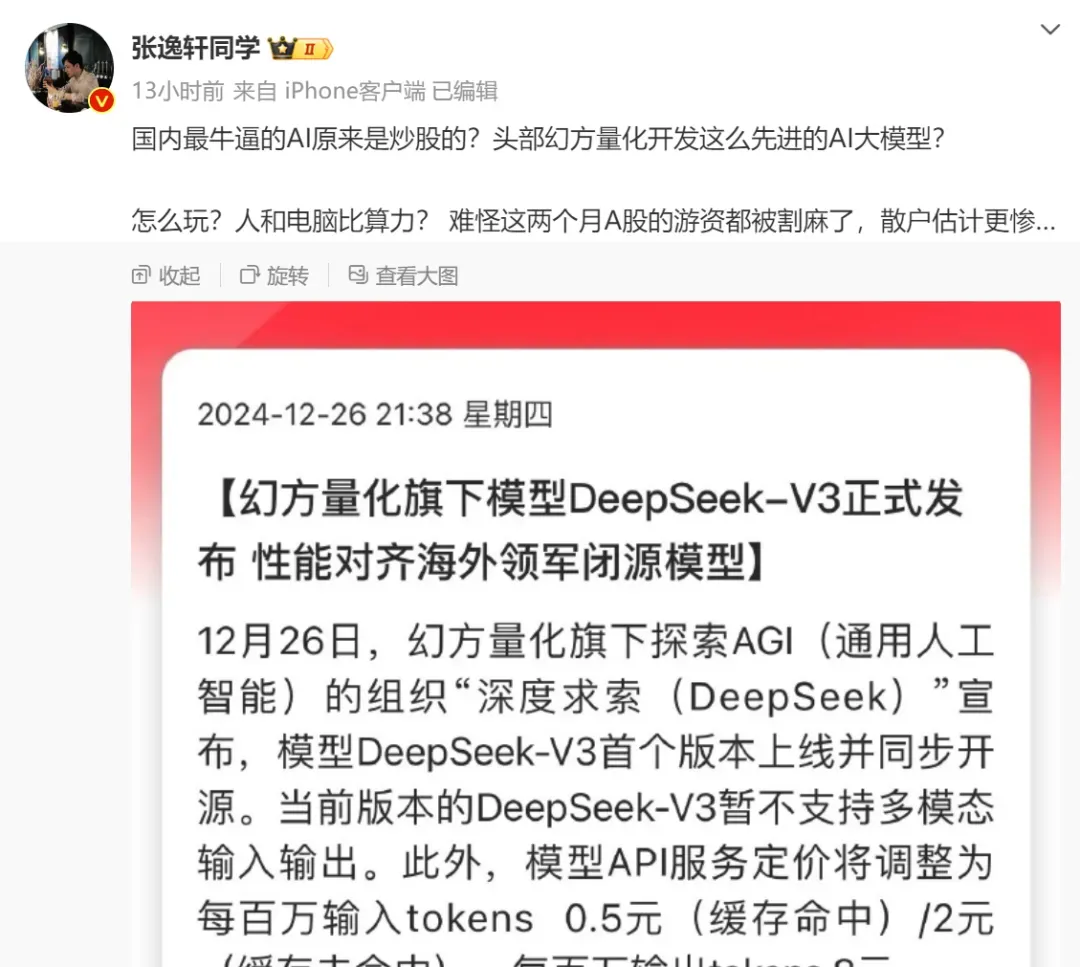
如斯历害的大模子,不是互联网科技巨头研发的,国内最牛的AI巨头(之一),的确是炒股的?
金融领域的头部量化:幻方量化。
梁文锋 是幻方量化的本色适度东说念主,他在DeepSeek最终受益的股份比例超80%。
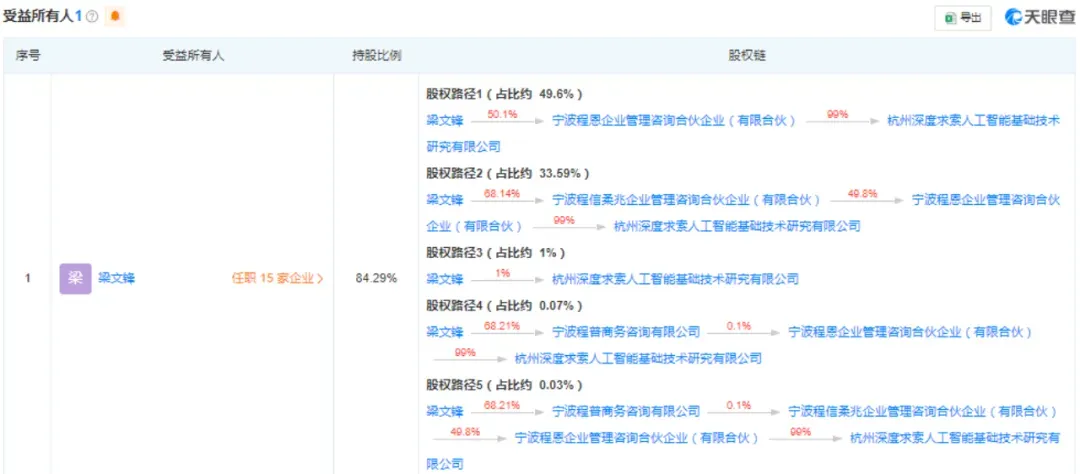
他本硕就读于浙江大学,攻读东说念主工智能,读书时就细则 「AI定会调动宇宙」。
毕业后,梁文锋莫得走智力员的既定阶梯,股票投资而是下场作念量化投资,确立幻方量化。幻方量化确立仅6年措置规模即曾达到千亿,被称为「量化四大天王」之一。
幻方量化亦然迄今为止,业内惟一规模曾迈过千亿大关的量化私募。
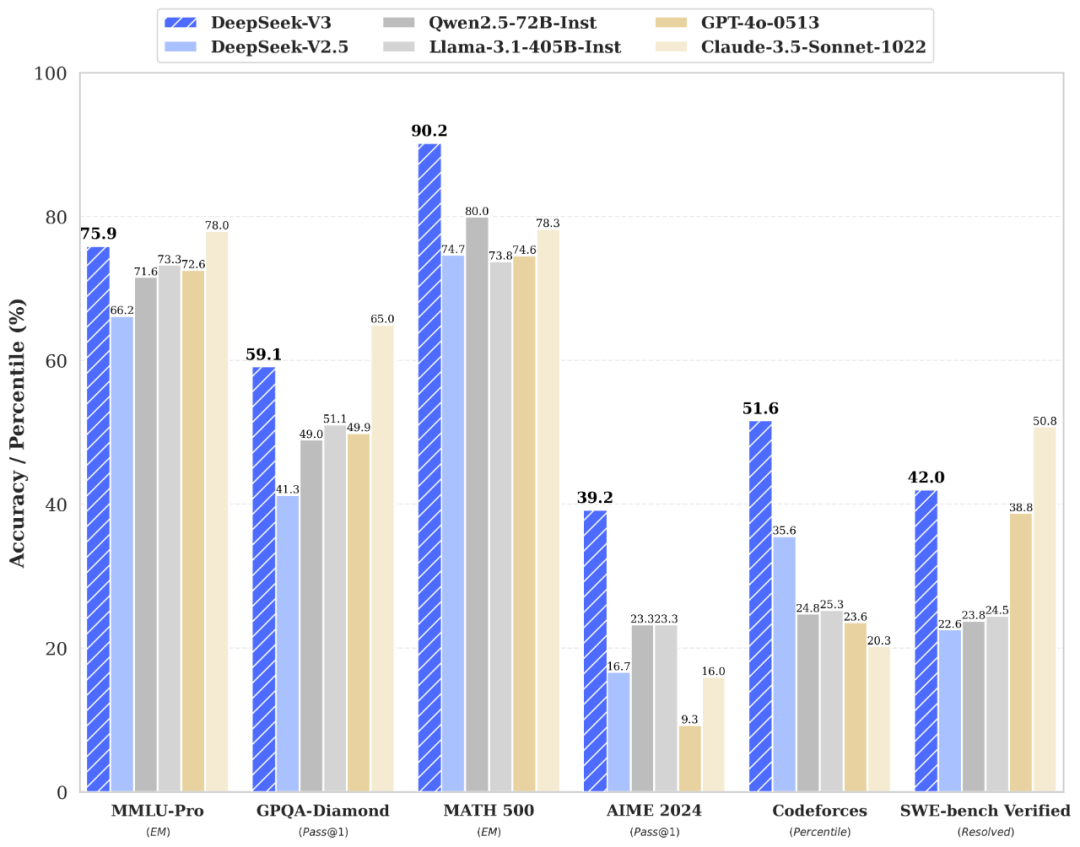
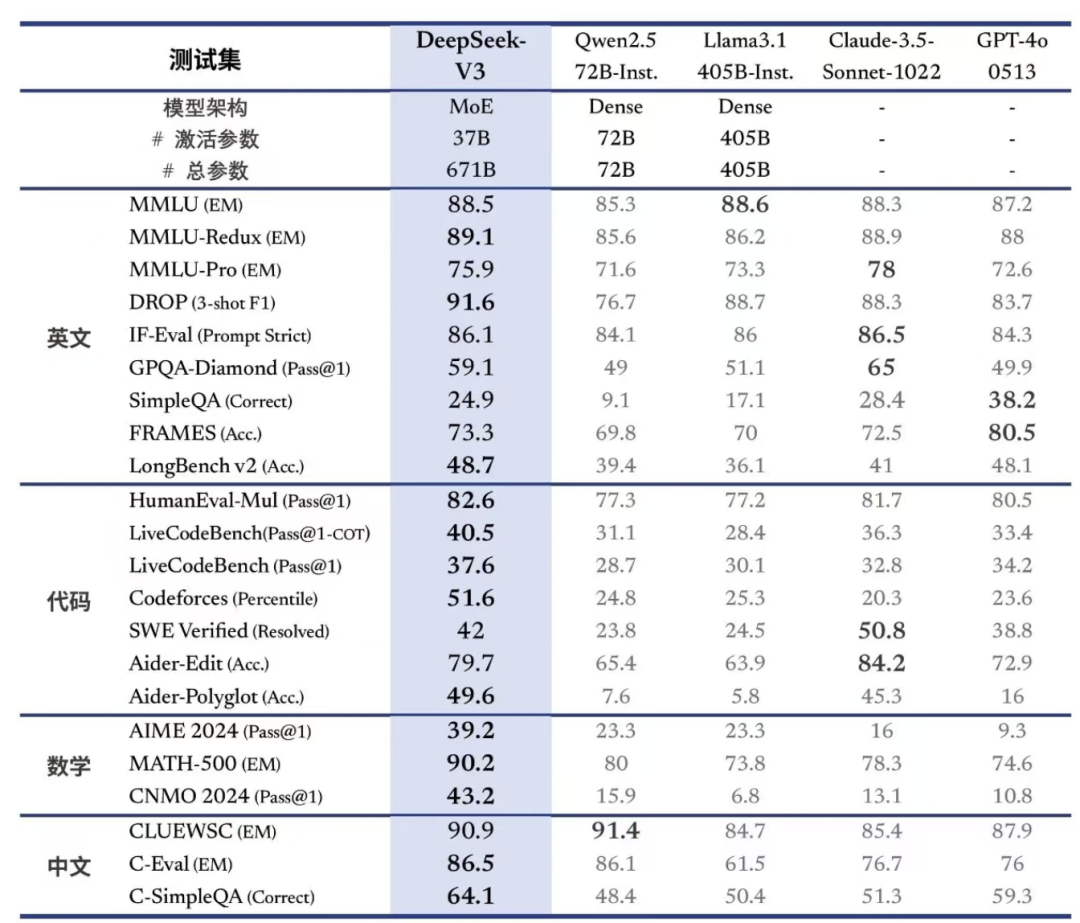
DeepSeek-V3 为自研 MoE 模子,671B 参数,激活 37B,在 14.8T token 上进行了预实践。
DeepSeek-V3 多项评测得益杰出了 Qwen2.5-72B 和 Llama-3.1-405B 等其他开源模子,在性能上和宇宙顶尖模子 GPT-4o 以及 Claude-3.5-Sonnet收支无几。
此前DeepSeek一直被冠以 “AI界拼多多”。
它开启了中国大模子价钱战。
2024年5月,DeepSeek发布的一款名为DeepSeek V2的开源模子,提供了史无先例的性价比:
推理资本被降到每百万token仅 1块钱,在那时约便是Llama3 70B的七分之一,GPT-4 Turbo的七十分之一。
随后,字节、腾讯、百度、阿里、kimi等AI公司随从降价。
面前,登录deepseek官网,即可与最新版 V3 模子对话。现时版块的 DeepSeek-V3 暂不复古多模态输入输出。
更新上线的同期,DeepSeek 转机了 API 工作价钱——模子 API 工作订价转机为每百万输入 tokens 0.5 元(缓存掷中)/ 2 元(缓存未掷中),每百万输出 tokens 8 元。
官方还为全新模子配置长达 45 天的优惠价钱体验期:
即日起至 2025 年 2 月 8 日,DeepSeek-V3 的 API 工作价钱仍然是每百万输入 tokens 0.1 元(缓存掷中)/ 1 元(缓存未掷中),每百万输出 tokens 2 元,照旧注册的老用户和在此时间内注册的新用户均可享受以上优惠价钱。
国内不少公司民俗于随从国外科技公司,参考技艺作念欺诈变现。
即使是互联网大厂在翻新方面也较为严慎,愈加嗜好欺诈层面。
DeepSeek逆向而行,聘请了一条更具挑战的说念路。它不温情于只是成为随从者,而是从架构翻新脱手,冷落了絮叨性的MLA架构,在全球AI大模子领域留住了独有的中国图章。
正如DeepSeek首创东说念主梁文峰所说:「中国也要迟缓成为孝顺者,而不是一直搭便车。」